
Index-TTS 语音克隆之王2.5 【纯净无广告版】最新整合包
简单介绍
IndexTTS2:情感表达与时长控制的自动回归零样本文本转语音的突破
摘要
现有的自回归大规模文本转语音(TTS)模型在语音自然性方面具有优势,但其逐字生成机制使得精确控制合成语音的时长变得困难。这在需要严格视听同步的应用中成为一个重要限制,比如视频配音。
本文介绍了IndexTTS2,提出了一种新颖、通用且适合自回归模型的语音时长控制方法。
该方法支持两种生成模式:一种明确指定生成的代币数量以精确控制语音时长;另一个则以自回归的方式自由生成语音,无需指定代币数量,同时忠实还原输入提示的韵律特征。
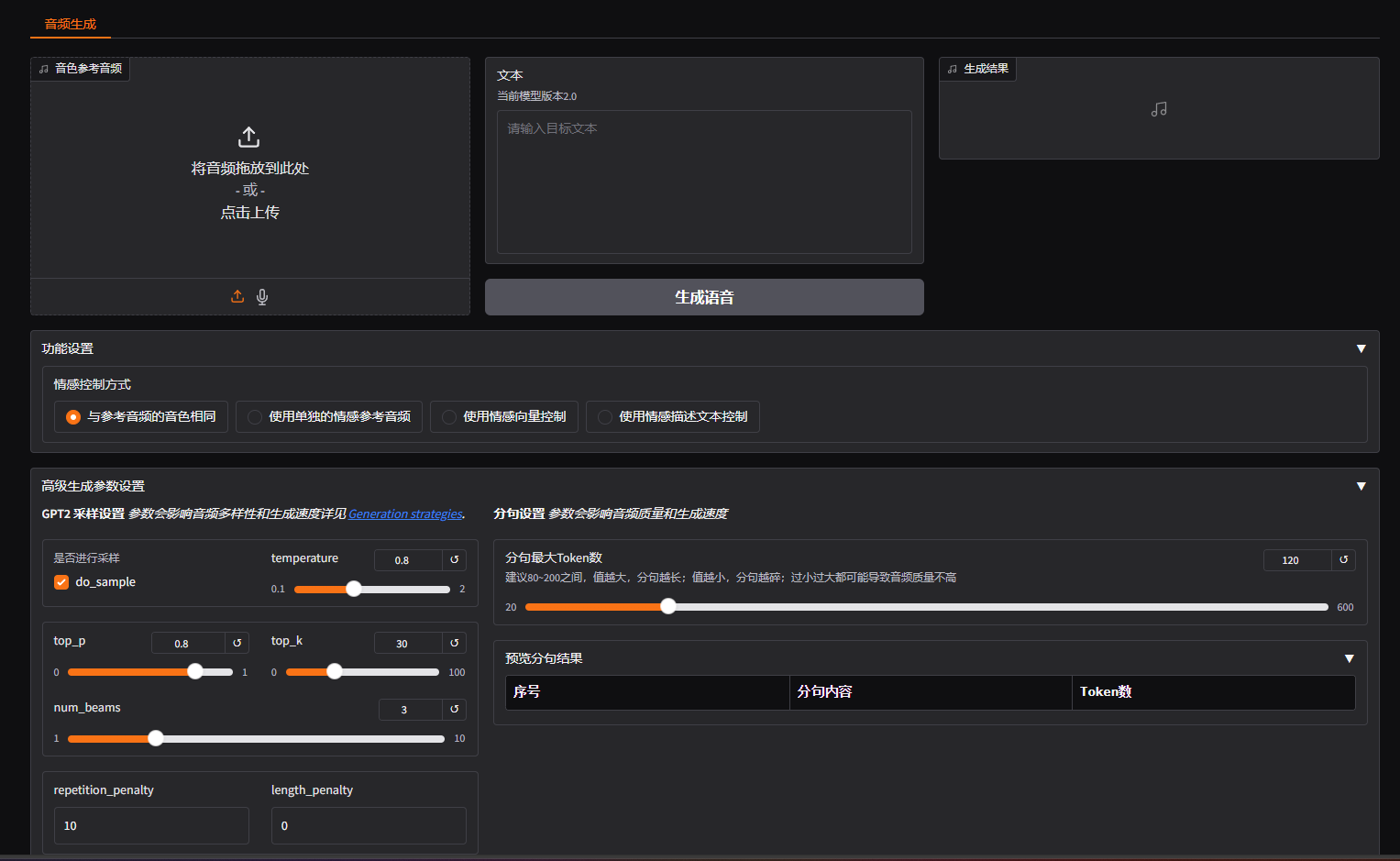
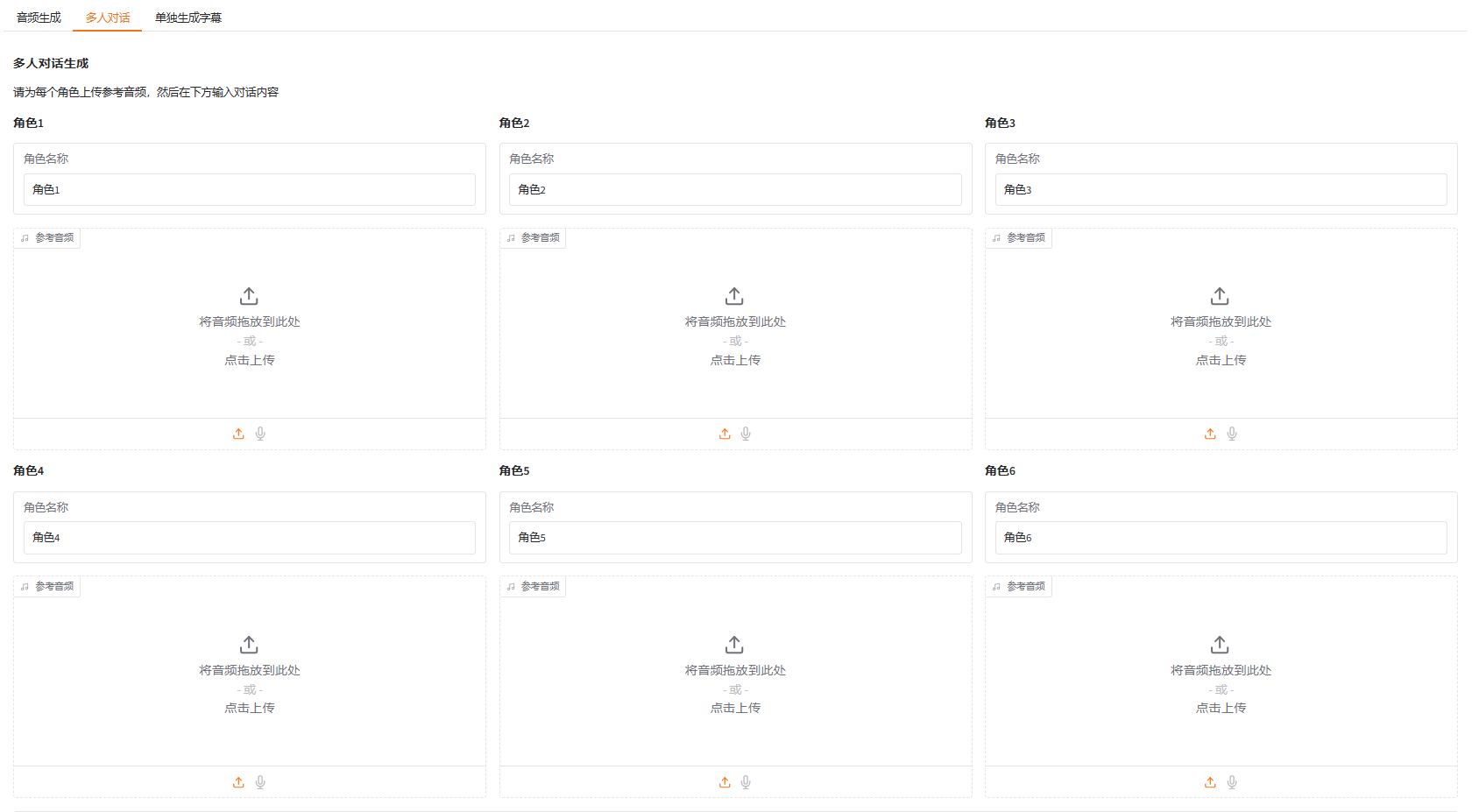
此外,IndexTTS2实现了情感表达与说话者身份的解离,实现对音色和情感的独立控制。在零镜头设置下,模型可以准确地重建目标音色(来自音色提示),同时完美重现指定的情感基调(来自风格提示)。
为了提升高度情绪化表达中的语音清晰度,我们引入了GPT潜在表征,并设计了一种新的三阶段训练范式,以提升生成语音的稳定性。此外,为了降低情绪控制门槛,我们通过微调Qwen3,基于文本描述设计了软指令机制,有效引导具有所需情感取向的语音生成。
最后,多个数据集的实验结果显示,IndexTTS2在词误率、说话者相似度和情感真实度方面优于最先进的零样本TTS模型。音频样本可在 IndexTTS2 演示页面获取。









